





高等学校や中学校の授業で機械学習を学ぶための教育プログラムを開発しました。
データサイエンスとは、データを分析・活用して、新たな価値を見つけ出す試みです。
例えば、売上に関連するデータを分析・活用して、未来の売上個数を予測する、売上を増やすために、お店はどのようなことをすればよいかなどを考察することが挙げられます。
データサイエンスが注目をされるようになった背景として、近年の情報化社会の発達により、多様なデータ、すなわちビッグデータを収集することが可能になったこと、そして、それらを分析するコンピューターの性能の向上、そして、インターネットをはじめとするネットワークを活用により、データのやり取りを効率的に行えるようになったことがあります。
データサイエンスは、単にデータを集計して、表やグラフにするだけではなく、それらを統計的性質(平均や分散)を求め、さらに、未来を予測するといった機械学習といった手法があります。本教育プログラムで開発した教材は、この機械学習の基礎を学ぶことを目標としました。
機械学習の種類には、教師あり学習、教師なし学習、強化学習などがあります。教師あり学習は、予め答えがあるもの(教師データ)に対して予測などを行うもので、回帰、分類といった手法があります。また、教師なし学習は、予め答えがないものに対してグループ化や変数変換などを行うもので、クラスタリングや次元削減といった手法があります。
(Google Colaboratoryを利用するため、GoogleアカウントとGoogle Colaboratoryの導入が必要になります。Google Colaboratoryの導入方法は、以下を参照してください。)
Google Colaboratoryの導入方法
まず、Google ChromeからGoogleドライブにアクセスし、以下の画面のように、「その他」の中にGoogle Colaboratoryがあるか確認してください。あればそれをクリックし、なければ、「アプリを追加」をクリックし、Colaboratoryを追加してください。
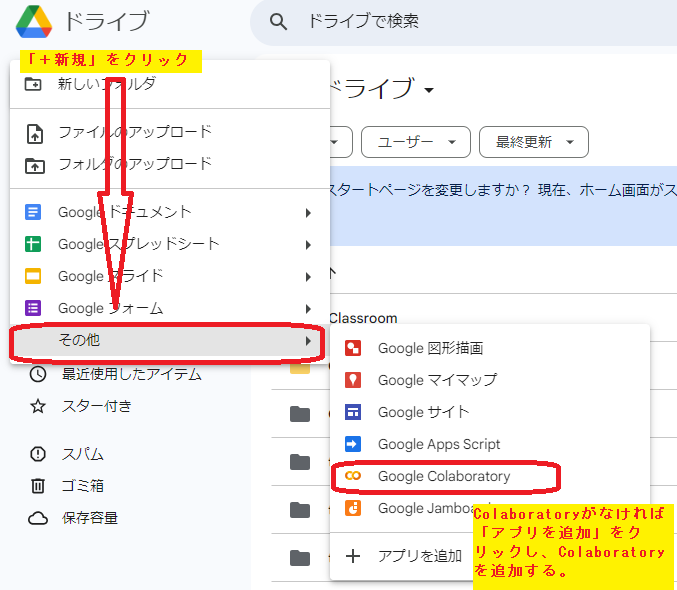
追加した場合は、以下のような画面が表示されることがあります。その場合は、一度ウィンドウを閉じて、再度Googleドライブにアクセスします。すると、今度は、Google Colaboratoryがあるので、クリックしてください。
Google Colaboratoryの動作確認
Google Colaboratoryの動かし方を確認しましょう。
Google Colaboratoryを起動すると、以下のような画面になっていると思います。

この灰色の部分を「セル」と言います。このセルの中に、以下に半角英数で以下のように入力し、Shiftキーを押しながらEnterキーを押してみましょう。
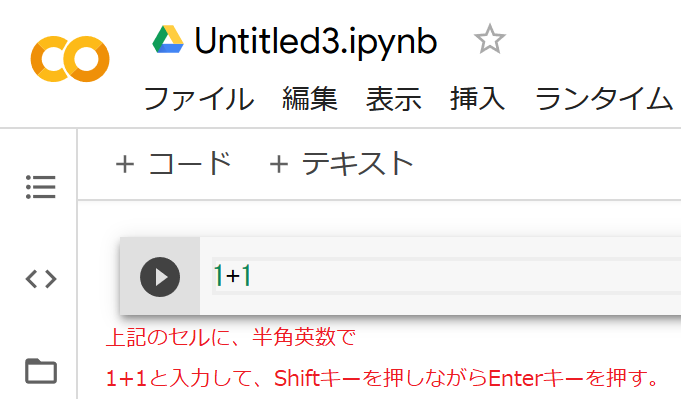
すると、その下に、「2」と表示され、さらに、新しいセルが表示されます。このようにしてプログラムを順番に実行していきます。
上記を含めて、いくつかのサンプルを用意したので、順番に実行してみてください(「警告: このノートブックは Google が作成したものではありません。」と表示されることがあります。これは、Google以外の人が作成したファイルを実行する場合、最初のみ表示されます。プログラムを実行したい場合は、「このまま実行」をクリックしてください)。
Google Colaboratoryの動作確認
機械学習を学ぶためのプログラムの紹介
ここでは、4つの機械学習のプログラムを体験してもらいたいと思います。回帰、分類、クラスタリング、次元削減の順番で紹介します。それぞれに共通する用語として、説明変数と目的変数があります。
説明変数:目的変数を説明するための変数。
目的変数:説明変数によって計算された変数
例えば、ある日のアイスクリームの売り上げ数が、その日の天候や最高気温、価格によって決まるとします。その場合、天候や最高気温、価格が説明変数になり、売り上げ数が目的変数になります。
以下のプログラムでは、分析データとして、独立行政法人統計センターが公開しているSSDSE(教育用標準データセット)を使用しています。
SSDSE(教育用標準データセット)
・回帰
教師あり学習の一つであり、説明変数から目的変数を予測するプログラムです。説明変数は一変数の場合もあれば多変数の場合もあります。目的変数も同様ですが一変数であることが多いです。目的変数は説明変数の値に応じて予め答えが設定されています。
回帰
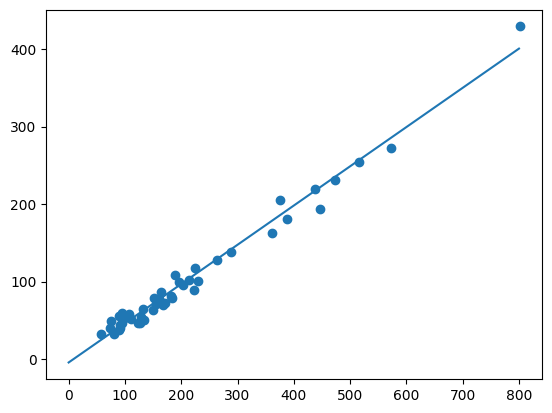
回帰の例。各都道府県の中学校数(x軸)から高等学校数(y軸)を推測。
・分類
教師あり学習の一つであり、説明変数から目的変数を予測するプログラムです。目的変数は説明変数の値に応じて予め答えが設定されています。回帰との違いは、目的変数が離散値(整数)であることです。
分類
・クラスタリング
教師なし学習の一つであり、説明変数から目的変数を予測するプログラムです。目的変数は分類と同様に離散値(整数)になります。分類との違いは、目的変数に予め答えが設定されていないことです。
クラスタリング

クラスタリングの例。各都道府県のりんごの年間支出額(x軸)とみかんの年間支出額(y軸)で散布図を作り、クラスタリングで3グループに分ける。
・次元削減
教師なし学習の一つであり、従来の説明変数を新たな説明変数に変換するプログラムです。その際、新たな説明変数の数が従来の説明変数の数より少なくなるようにします。
次元削減
関連リンク
・アプリURL(お茶の水女子大学附属学校における理系女性育成のための新たな教育プログラム開発)
